面向对象编程的三大特性
封装
将对象不需要让外界访问的成员变量和方法私有化,只提供符合开发者意愿的公有方法来访问这些数据和逻辑,保证了数据的安全和程序的稳定。
java通过权限修饰符来控制类成员的访问权限,各修饰符的访问权限如下:
| 修饰符 | 当前类 | 同一个包 | 子类 | 其它 |
|---|---|---|---|---|
| private | √ | |||
| 默认 | √ | √ | ||
| protected | √ | √ | √ | |
| public | √ | √ | √ | √ |
继承
继承是指从已有的类中派生出新的类,新的类拥有父类非私有的属性与方法。继承的类叫做子类(派生类),被继承的类叫做父类(超类或者基类)。
多态
多态是同一个行为具有多个不同表现形式或形态的能力。多态的优点:
- 消除类型之间的耦合关系
- 可替换性
- 可扩充性
- 接口性
- 灵活性
- 简化性
在Java中多态的两种主要形式:继承(多个子类对同一方法的重写)和实现(接口实现)
Java的基本数据类型
| 数据类型 | boolean | byte | char | short | int | long | float | double |
|---|---|---|---|---|---|---|---|---|
| bit | 32 | 8 | 16 | 16 | 32 | 64 | 64 | 64 |
| 最小值 | - | -2^7 | -2^15 | -2^15 | -2^31 | -2^63 | -2^63 | -2^63 |
| 最大值 | - | 2^7-1 | 2^15-1 | 2^15-1 | 2^31-1 | 2^63-1 | 2^63-1 | 2^63-1 |
| 包装类型 | Boolean | Byte | Character | Short | Integer | Long | Float | Double |
基本类型的两条准则:
- 对整型数据不指定类型默认为int类型,浮点数默认为double类型
- 基本数据类型从小(字节)到大可以自动转换,从大到小需要进行类型强制转换(cast)
boolean类型会在编译时期被JVM转换为int,true为常量值1,false为0,如
boolean a = true;查看字节码(javap -verbose xxx.class)会发现iconst_1指令,是指把int常量值1压入栈中,因此boolean需要4个字节进行存储。使用int的原因是对于当下32位的处理器(CPU)来说,一次处理数据是32位。而boolean数组会被编译为byte数组,故作为数组时,数组中的每个boolean元素只占一个字节。
基本类型都有对应的包装类型,且对应的包装类型都被final标识,不可被继承。基本类型与包装类型之间的转换自动装箱与拆箱完成:
1 | Integer a = 5; // 装箱调用Integer.valueOf(2) |
在 Java 8 中,大部分基本类型都有缓存值,如Integer通过其内部类IntegerCache的cache[]缓存了-128~127范围值。
1 | /** |
当使用装箱方式初始化Integer时,若初始值是在缓存范围内,则会引用缓存范围内的对象。从上源码注释可以看出,Integer可以通过在启动jvm时添加-XX:AutoBoxCacheMax=<size>设置其缓存大小,但其它基本类型是没有相应的设置方式的。
1 | Integer a = 5; |
各基本类型对应包装类型的缓存池值(Double、Float没有缓存)如下:
- Boolean: 通过字段缓存true,false
- Byte:内部类ByteCache缓存所有字节(-127-128)
- Short:内部类ShortCache缓存-127-128
- Integer:内部类IntegerCache缓存-127-128
- Long:内部类LongCache缓存-127-128
- Character:内部类CharacterCache缓存0~127对应的ASCII码字符值
运算小题目
1 | char a = 'a'; // 'a'的ASCII码为97 |
那么问题来了,e是多少呢?运算过程中类型是怎么转换的呢?请务必让我根据下图一一讲解: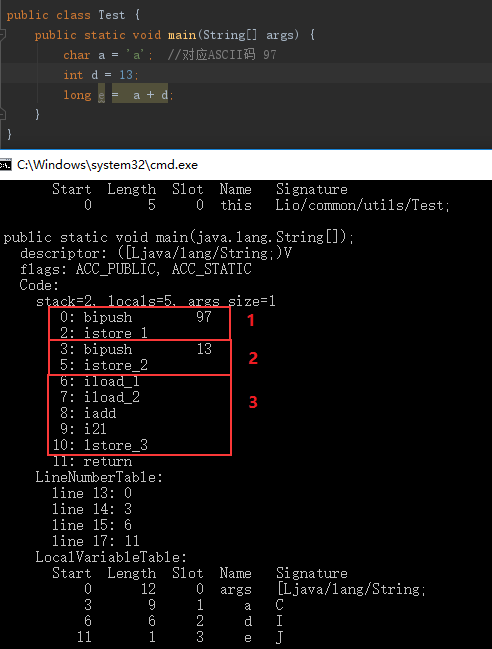
(上图为在类编译结果目录target/pagkage执行javap -verbose Test显示的字节码)
- bipush将a转换为int值(‘a’对应的ASCII码值)入栈,istore_1取出栈顶int值(即a值)保存到局部变量1中
- bipush将b(b本身为int,无需转换)入栈,istore_2取出栈顶int值(即b值)保存到局部变量2中
- iload_1、iload_2将局部变量1、2的int类型值入栈,iadd将栈顶的2个int值相加,并将结果压栈,i2l将int转long(不是i2十一哦),然后lstore_3将栈顶long值保存到局部变量3中
引用数据类型
java的引用类型只有三种,分别是类(class)、接口(interface)、数组。当某一引用数据内容在其中一个作用域被改变时,其它作用域中该引用数据内容也会发生改变。
JVM内存区域主要为堆和栈,栈可以说是方法执行的内存模型,当在方法里定义一个变量时,栈就会为该变量分配内存空间,当超出变量的作用域时,其分配的栈空间就会被释放。栈的存取速度比堆要快,仅次于寄存器,但存在栈中的数据大小与生存期必须是确定的,故Java的8种基本数据类型和对象引用变量都是存放在栈中(设想下若对象存放到栈中,那么传对象参数时每传递到一个方法就会导致上一个方法对对象的回收,导致含一定大小的内存回收频繁降低程序性能,故使用堆存放对象)。
堆是所有的对象实例以及数组分配内存的运行时数据区域,即使对象已经没有在任何地方被引用了占用的空间也不会马上被释放,而是等到触发某些条件(如手动调用System.gc()、新生代空间不足、老年代空间不足等)才会被回收器回收。
引用测试例子:
1 | public class Test { |
关键字
final:常量关键字
- 数据:声明数据为常量,可以是编译时常量,也可以是在运行被初始化后不能被改变的常量。
- 对于基本类型,final使数值不变
1
2final a = 1;
a = 2; // cannot assign value to final variable 'a' - 对于引用类型,final使引用不变,即不能引用其它对象,但是被引用的对象本身内容是可以被修改的。
1
2final String str = "b";
str = "c"; // cannot assign value to final variable 'str'
- 对于基本类型,final使数值不变
- 方法:声明方法不能被子类重写,private方法隐式地被指定为final。
- 类:声明类不允许被继承。
static:静态关键字
静态变量
又称类变量,表示变量属于类(Class对象)的。静态变量在内存中只存在一份,在类的所有实例对象都共享静态变量,可以直接通过类名来访问它,静态变量在内存中只存在一份。
- 实例变量:实例对象内非static标识的的属性变量。
1
2
3
4
5public class A {
private int x; // 实例变量
private static int y; // 静态变量
}
静态方法
静态方法在类加载阶段初始化,不依赖于任何实例对象,所以静态方法不能是抽象方法,也不能通过this调用静态方法。
标识代码块:静态语句块
静态语句块只会在类(Class)初始化时运行一次。
1 | public class A { |
静态内部类
非静态内部类依赖于外部类的实例,即需先创建外部类实例,才能用这个实例去创建非静态内部类,而静态内部类不需创建外部类。
1 | public class OuterClass { |
类初始化顺序
- 父类静态变量->静态代码块
- 子类静态变量->静态代码块
- 父类实例变量->普通代码块->父类构造函数
- 子类实例变量->子类代码块->子类构造函数
1 | public class SingleTon { |
Object
Object是所有类(包括数组)的基类,是唯一没有父类的类。
clone()
作用域是protected,若不重写该方法并声明为public则非类作用域中的对象则无法调用该方法。Cloneable接口只规定如果类没有实现该接口又调用了clone(),就会抛出CloneNotSupportedException。
- 浅拷贝:拷贝对象和原始对象的引用类型引用同一个对象。
- 深拷贝:拷贝对象和原始对象的引用类型引用不同对象。
hashCode()
返回对象的哈希值,equals()返回true则两个对象hashCode一定相同,但hashCode相同的两个对象不一定equals。AbstractList、AbstractSet和HashMap.Node等集合类使用了hashCode()方法来计算对象的存储位置,因此要将对象添加到这些集合类中,需要让对应的类实现 hashCode() 方法。hashCode的特点如下:
- hashCode是用来在散列存储结构中确定对象的存储地址(如集合中的HashMap、AbstractList及子类、AbstractSet及子类)
- 如果两个对象equals()返回true,则这两个对象的hashCode必须要相同
- 如果重写了类的equals()方法,hashCode()方法也必须要重写
- 两个对象的hashCode相同不代表两个对象相同,只能说明这两个对象在散列存储结构中
散列存储:又称hash存储,是一种将数据元素的存储位置与关键码之间建立确定对应关系的查找技术。
综上,hashCode是用于查找使用的,而equals是用于比较两个对象的是否相等的。以HashMap.get(Object key)调用的getNode(int hash, Object key)为例:HashMap通过hashCode确认了查找对象的大概位置,再根据hashCode与key确定对象的实际位置。可以理解为HashMap根据hashCode划分成一个个桶,每个桶里含相同hashCode的对象,通过hashCode确认对象的大概位置后,再通过等值判断(1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
// 1.判断Node数组table是否为空并数组长度大于0,且通过hashCode获取的数组下标位置元素不为空
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 2. A:判断hash获取的下标位置起的第一个Node元素hash值是否与参数的hash值相同、Node.key是否与Node参数key地址相同,B:或Node.key是否与参数key内容相同且参数key不为空,满足A或B其中一个条件则返回hash获取的下标位置起的第一个元素
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 如果hash获取指定下标的第一个Node并非所需要的Node,则根据Node元素的实例是否为TreeNode来确定查找方式
if ((e = first.next) != null) {
// TreeNode查找方式获取指定key元素Node
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
// 链表方式查找指定key元素Node
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}==或equals())获取所需元素Node,所以集合类的对象都要主要重写hashCode方法。
equals():判断两个对象是否具有等价关系
String
String被声明为final,因此是不可被继承的(Integer 等包装类也不能被继承)。在 Java 8 中,String 内部使用char数组存储数据。
1 | private final char value[]; |
value[]被声明为 final,意味着value[]初始化之后就不能再引用其它数组。并且 String 内部没有改变value[]的方法,因此可以保证String不可变。不可变的特性可以使得 hash 值也不可变,使String十分适合作为集合类(如HashMap、HashSet)的哈希运算。
String有以下两种赋值方式
- 字面量赋值(“Hello”字符串存到常量池中):
String str = "Hello"; new创建新对象():String str = new String("Hello");,new方式会在编译时期在String Pool中创建一个字符串对象指向字面量”Hello”(即字符串引用),在运行时会在堆中创建一个字符串对象,该字符串对象intern()返回该字符串字面量的引用。
字符串常量池(String Pool)保存着所有字符串常量,这些字面量在编译时期就确定,也可以使用 String的intern()方法在运行过程将字符串添加到String Pool中。在 Java 7 之前,String Pool 被放在运行时常量池中,它属于永久代。而在 Java 7,String Pool 被移到堆中,字符串常量池中存放的是字符串的引用。
如下例,通过字面量赋值时,加载阶段会在堆区中创建一个字符串对象”Hello”,同时在字符串池(String Pool)中存放一个它的引用,当赋值变量str时,虚拟机会去字符串池中查找是否含equals(“Hello”)的字符串,如为true则返回字符串池中的引用,如果找不到equals的字符串,就会在堆中新建一个对象,同时把引用驻留在字符串池,再把引用赋给str。
1 | public class Test { |
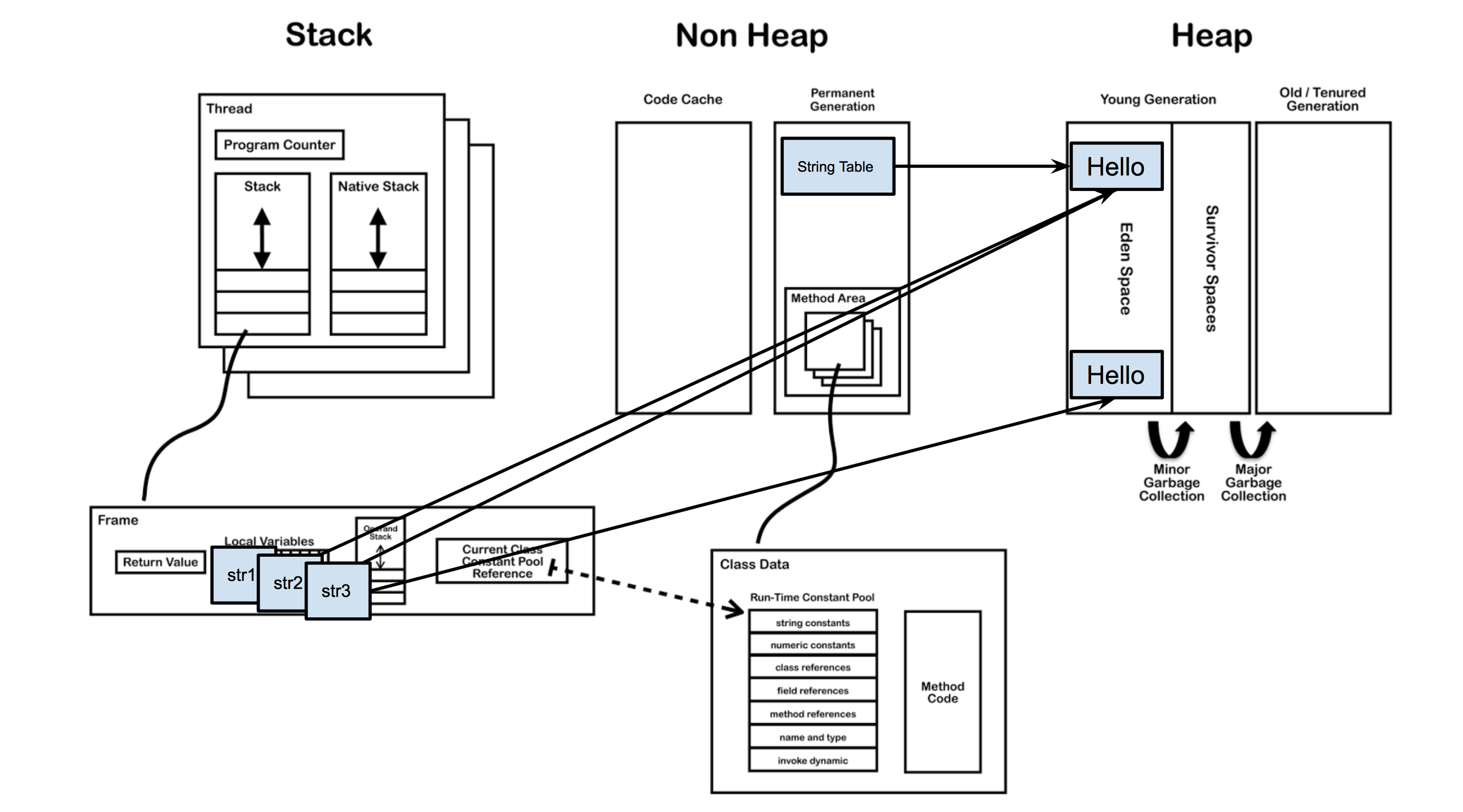
1 | String s1 = "Hello"; |
- intern():如果字符串常量池中已经含与当前对象equals(object)为true的字符串,则返回池中的字符串引用;否则将当前String对象添加到字符串常量池中,并返回对当前String对象的引用。
String, StringBuffer和StringBuilder
- String、StringBuffer和StringBuilder都是通过char数组存储数据,不过StringBuffer和StringBuilder的char数组可变的,没有被final修饰
- StringBuffer线程不安全,String由于其不可变所以是线程安全的,StringBuffer的方法都使用了synchronized同步所以是线程安全的
- String相加编译为字节码后都会新建StringBuilder来进行字符串拼接
反射
编译器在编译期间将类文件编译为字节码.class文件,在类运行的加载步骤中的加载阶段会根据.class文件生成对应的Class对象并存放到堆中,而字节流的静态存储结构则转化为方法区的运行时数据结构(存储如类的字段、方法等信息)。
反射可以提供运行时的类信息,并且这个类可以在运行时才加载进来,甚至在编译时期该类的.class不存在也可以加载进来。java反射相关类主要都在包java.lang.reflect下,反射相关常用类如下:
- Class:Class对象代表运行的Java应用中的类和接口(枚举enum是一种类,注解annotation是一种接口),可以通过Class对象获取类和接口的信息(如类名、所在包、属性、方法、注解等)
- Field:提供有关类或接口的单个字段及对它们动态访问的信息(注解、类型),可通过Class对象获取
- Method:提供有关类或接口上的单个方法的信息(参数、注解),以及对单个方法的访问调用。反射获取的方法可以是类方法或实例的方法,调用
invoke()方法调用。 - Constructor:提供类的构造函数信息(参数、注解),并提供对此类的访问,通过调用该对象的
newInstance()可以创建声明类的实例。 - Parameter:提供方法参数的信息(类型、注解),可通过Method、Constructor对象获取。
虽然反射的功能很强大,但也不该滥用,反射的缺点如下:
- 增加性能开销:反射涉及了动态类型的解析,JVM无法对这些代码进行优化,因此反射效率比直接操作的效率是慢很多的
- 安全性降低:由于反射可以执行一些正常情况下不被允许的操作(如访问私有属性和方法),破坏了封装性
异常
Throwable 是所有异常类的基类,java根据异常是否虚拟机异常将异常分为Error与Exception,Throwable的一级子类只有Error与Exception。
- Error:合理的应用程序不应尝试捕获的严重问题,一般是虚拟机的异常,如栈溢出(StackOverFlowError)、内存溢出(OutOfMemoryError)
- Exception:合理的应用程序可能需要捕获的异常,常见的Exception子类有SQLException、RuntimeException、IOException等
PlantUML Web Server
Exception异常有两种处理方式: - 捕获处理:
try{} catch{}捕捉处理且不抛出throw使程序正常运行 - 抛出异常:通过
throw/throws抛出异常将结束当前程序代码块的运行将异常抛给上游(方法调用方),由上游进行处理,常见的业务异常可以通过Spring Boot的@ControllerAdvice定义全局异常拦截器
注解-Annotation
Annontation是JDK5引入的特性,用于将一些信息或元数据标注到程序元素(类、方法、成员变量、参数等),可以理解成程序元素的标签。注解标注的元数据可用于编译、类加载、运行时使用,元素的注解相关类都包含在java.lang.annotation包中。
注解本质是一个继承了 java.lang.annotation.Annotation 的特殊接口(注解即接口),其具体实现类是Java 运行时生成的动态代理类。通过反射获取注解时,返回的是Java 运行时生成的动态代理对象$Proxy1。通过代理对象调用自定义注解(接口)的方法,最终会调用 AnnotationInvocationHandler 的invoke 方法,该方法会从memberValues 这个Map 中索引出对应的值,而memberValues 的来源是Java 常量池。
元注解
java.lang.annotation提供了四种元注解,用于注解其他的注解(常用于自定义注解):
@Documented:注解是否将包含在JavaDoc中
@Retention:注解的保留时间,默认保留策略为
RetentionPolicy.CLASS,注释可选的保留策略RetentionPolicy如下:SOURCE:注解只在源文件中.java保留,编译后丢失(即编译后的.class文件将不包含注解)CLASS:注解保留到编译文件,但VM不会在运行时保留这些注解RUNTIME:注解由VM保留到程序运行期间,因此程序运行时可以通过反射获取这些注解信息
@Target:声明注解适用的范围,参数为
ElementType注解范围枚举数组,ElementType常用枚举如下:TYPE:类,接口(包括注解)或枚举FIELD:字段METHOD:方法PARAMETER:参数CONSTRUCTOR:构造函数LOCAL_VARIABLE:本地变量ANNOTATION_TYPE:注解PACKAGE:包
@Inherited:声明注解是可继承的,如A类被可继承的注解B标注了,AA集成了A,则B注解也对A有效

